How I Version Control My Resume Without Latex
As a person whose day to day work involves a lot of code, that means I’m also a person who uses version control (git) for pretty much any project. So I keep my resume under version control so I can track changes.
When you Google something about keeping a resume in version control, using LaTeX comes up over and over again. Using LaTeX involves learning a markdown languange which generates your resume for you. It’s basically resume-as-code, which means it’s pretty complex for anyone who doesn’t already know LaTex (which I do not). I just want to keep my resume in a git repo, I don’t want to learn a whole new markdown languange just so I can track a few resume changes per year.
So I don’t use LaTeX.
I use a plain old text file
Actually, I use a Libre Office .odt file, which is where I make changes to my
resume. Then I do File -> Export as PDF and save my resume as a PDF, which is
what I host on S3 and what I send when I apply for jobs. I also File -> Save as
a .doc file, just in case someone specifically requests a .doc file. All of
those formats (.odt, .pdf, .doc) are binary files and play terribly with git.
So I also File -> Save as and save my document as a plain text .txt file.
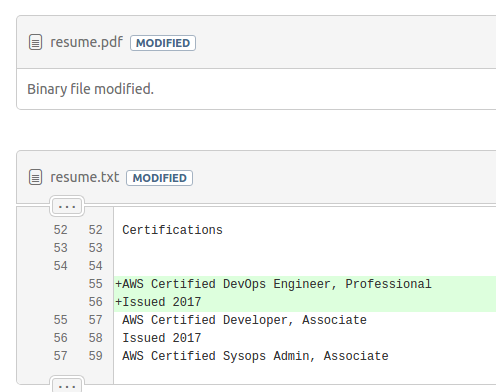
I can commit all of these files to git, but the .txt file is the one that is useful for tracking changes. I can view my commit history on Bitbucket and track all my changes right there.
Deploying changes with each commit
I use S3 to host a static copy of my resume, which is useful when recruiters call and say “Hey, it’s been a while since we touched base. I have a copy of your resume from 8 years ago and…” I can just refer them to the domain name where I host my PDF. (Side note, why do they always do this over the phone and not email?!)
Anyway, since I’m hosting a copy of my resume on S3, and since I’m storing my
resume in git with Bitbucket, I can also let Bitbucket deploy my changes to S3
for me. Pushing a PDF to S3 isn’t a lot of work if I did it manually, but letting
Bitbucket do it for me ensures that I don’t forget. Any change to master also
gets pushed to S3.
I won’t go through every single step of how to make Bitbucket deploy my changes for me, but it’s based on Bitbucket Pipelines, then use a bitbucket-pipelines.yml script like this:
image: fstab/aws-cli
pipelines:
default:
- step:
script:
- aws --region us-east-1 s3 sync $BITBUCKET_CLONE_DIR s3://MY-BUCKET/ --exclude '.git/*'
The image is a Docker container that includes awscli already installed. My
AWS access key and secret key (for this one bucket, not my root account) are
stored as environment variables in Bitbucket. Bitbucket Pipelines spins up a
container on each commit and pushes my changes to my S3 bucket.